View Case Study
AI Development & Automation Technology & Startups
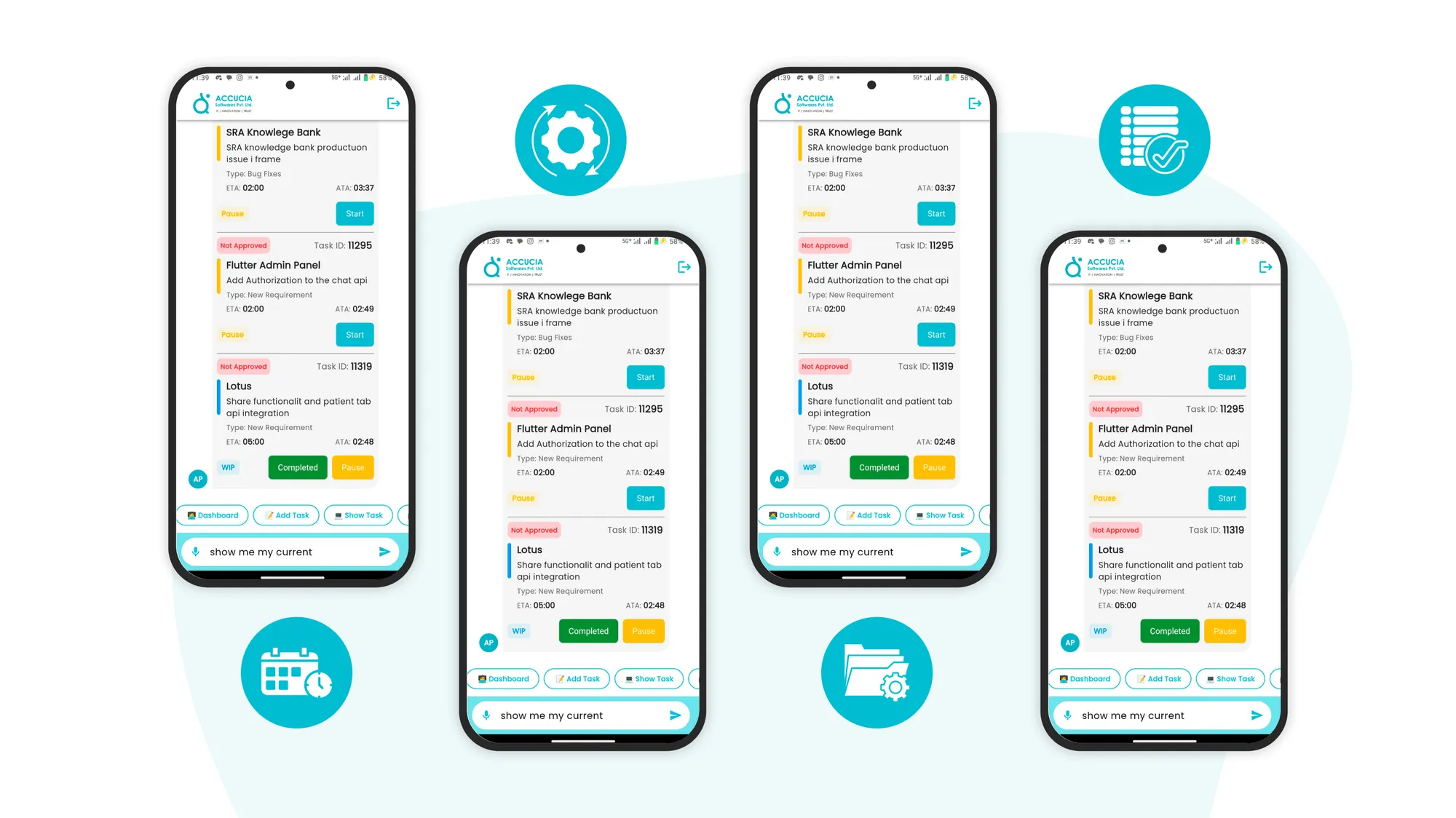
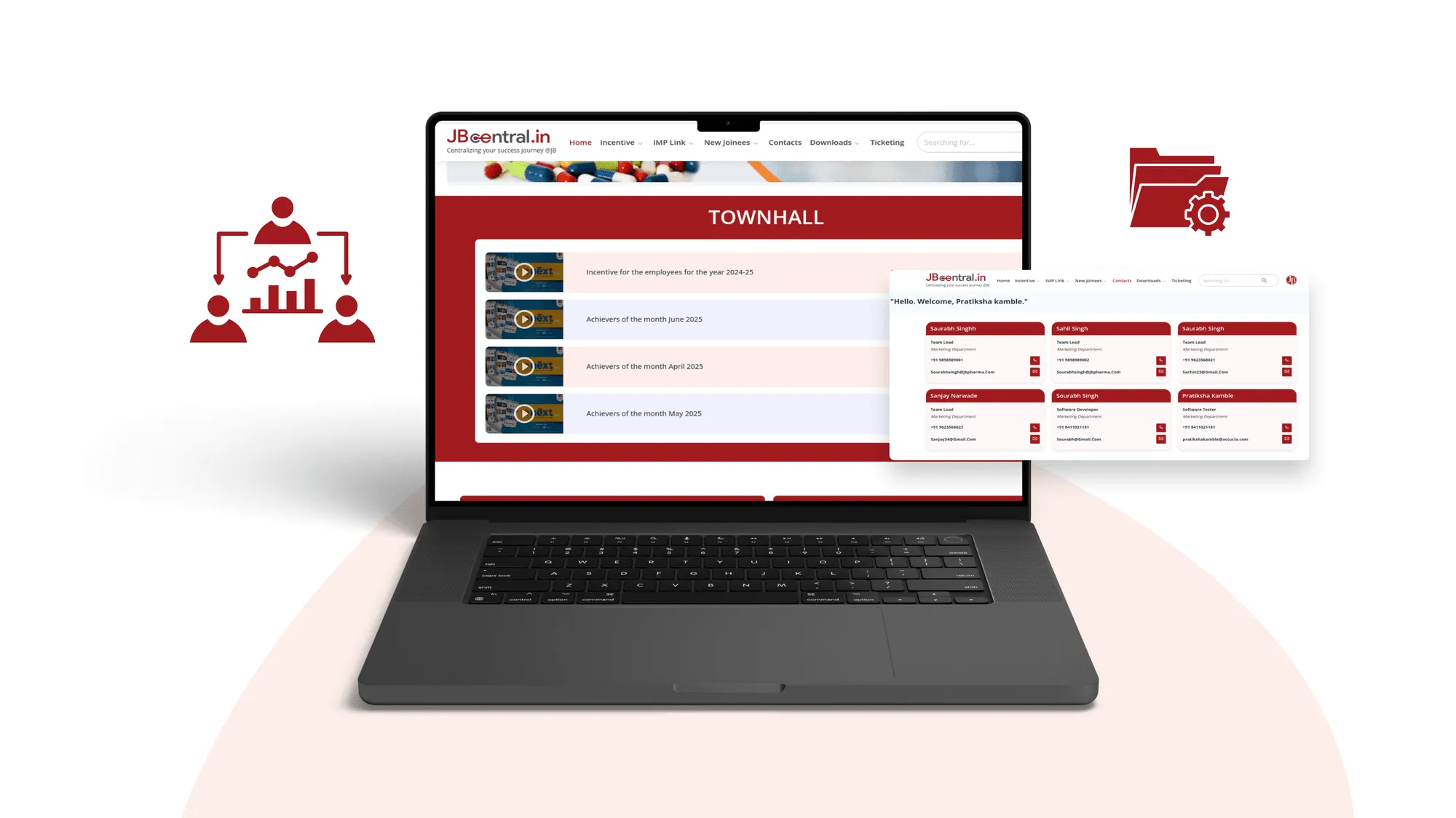
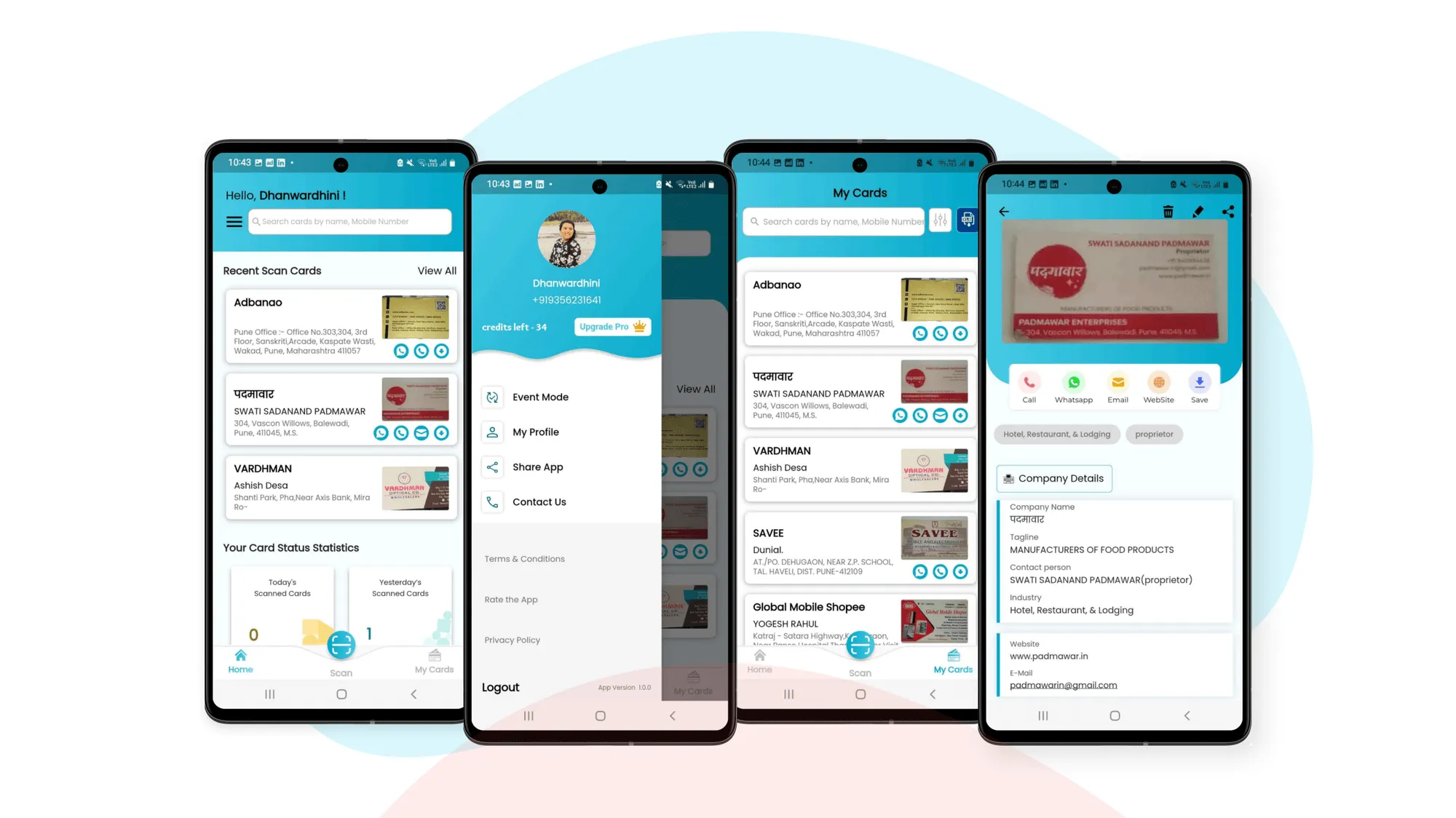
Card Scanner - Business Card Digitization App
A powerful AI-powered business card scanner app with freemium model, enabling instant digitization of business cards, CRM integration, and event management capabilities. Available on Android and iOS with API access for seamless integration.